CORDS — Energy and Time Efficient Toolkit for Training Large Datasets

In this Article
- Introduction
- What is CORDS?
- Getting started with CORDS
- CORDS Demo
- Code Walk-through
- CORDS Results
- Conclusion
- Publications
1. Introduction
With the growth of computers, there is substantial growth in data. In today’s world, machine learning tasks often involve using large neural networks which require access to high-end GPUs to train large datasets which is expensive and takes a lot of time to train to achieve good accuracy. When there are limited resources and time, it may then pose a problem. This tutorial has a solution for handling these large datasets.

2. What is CORDS?
CORDS is a toolkit that is based on the PyTorch library that allows researchers and developers to train models by reducing the training time from days to hours (or hours to minutes) and energy requirements/costs by an order of magnitude using coresets and data selection. The goal of CORDS is to make machine learning time more energy, cost, resource and time efficient while not sacrificing accuracy. The idea behind cords is to select right representative subsets of large datasets using state of the art subset selection and coreset algorithms like -
- GLISTER [1]
- GradMatch [2]
- CRAIG [2,3]
- Submodular Selection [4,5,6] (Facility Location, Feature Based Functions, Coverage, Diversity)
- Random Selection
3. Getting started with CORDS
To get started with CORDS, click here to access the GitHub repository and follow the installation procedure
4. CORDS Demo
For this demo we will cover the basics of CORDS using GLISTER strategy by training on the Cifar10 dataset. Cifar10 is a classic dataset for deep learning, consisting of 32x32 images belonging to 10 different classes, such as dog, frog, truck, ship, and so on. Training a complete dataset on ResNet architecture takes a couple of hours. The mission is to reduce the training time and costs without sacrificing accuracy.
NOTE: Here for this example, we have used GLISTER strategy with Cifar10 dataset and ResNet architecture. It is possible to run any strategy
Step 1
Modify the model architecture in the following way:
- The forward method should have two more variables:
- A boolean variable ‘last’ which -
▹ If true: returns the model output and the output of the second last layer
▹ If false: Returns the model output.
- A boolean variable ‘freeze’ which -
▹ If true: disables the tracking of any calculations required to later calculate a gradient i.e skips gradient calculation over the weights
▹ If false: otherwise
2. get_embedding_dim() method which returns the number of hidden units in the last layer.

Step 2
Use a configuration file as shown below with required parameters (config_glister_cifar10.py)

Step 3
Run the below code
from train import TrainClassifierconfig_file = “configs/config_glister_cifar10.pyclassifier = TrainClassifier(config_file)classifier.train()
VOILA! Training has never been as simple as this!
In the next section we go through the complete training procedure step-by-step for the code train.py.
5. Code Walk-through
Highly modularized code of CORDS makes developers and researchers simple to understand and make changes as required for their needs.
Initially, define the model with the required model architecture:

Define the loss function and optimizers in the same way
The train method incorporates following steps:
▹ Load the training, testing and validation dataset and declare batch sizes for the corresponding datasets.
▹ Load the dataset using PyTorch DataLoader object for training, testing and validation which takes care of shuffling the data (if required) and constructing the batches.
▹ The next step is to initialize the data subset selection algorithm
▹ In the next step we train the network on the subset of the training data. We simply have to loop over the data iterator for the required number of epochs and feed the inputs to the network and optimize. The subset selection algorithm returns the right representative data subset indices and corresponding gradients. These are then loaded into PyTorch DataLoader object for further evaluation.

▹ In the next step, we evaluate the model losses on the subset of the training data
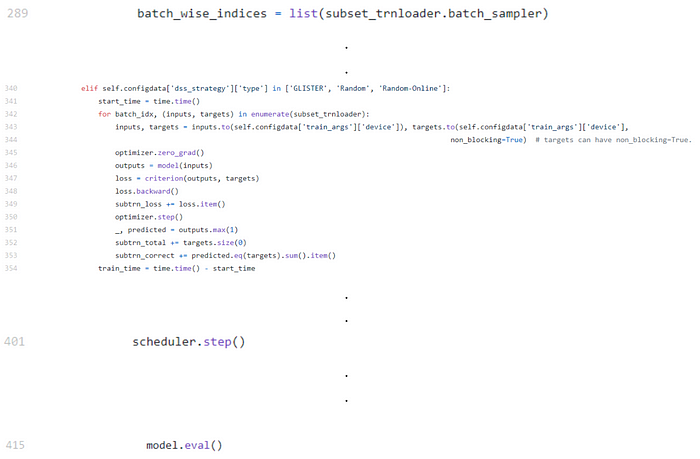
▹ At last, we calculate the validation and test losses for validation and test datasets loaded using PyTorch DataLoader objects
6. CORDS Results
Currently we see between 3x to 7x improvements in energy and runtime with around 1–2% drop in accuracy. We expect to push the Pareto-optimal frontier even more over time.
7. Conclusion
As seen, CORDS is an effort to make deep learning more energy, cost, resource and time efficient while not sacrificing accuracy.
The following are the goals CORDS tries to achieve:
- Data Efficiency
- Reducing End to End Training Time
- Reducing Energy Requirement
- Faster Hyper-parameter tuning
- Reducing Resource (GPU) Requirement and Costs
In this part, we discussed the basic introduction to CORDS and how it can be used for subset selection for massive datasets. In the next tutorial we will talk about hyper-parameter tuning to obtain SOTA results using CORDS (click here).
For more examples and tutorials, visit the CORDS GitHub repository.
8. Publications
[1] Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer, [GLISTER: Generalization based Data Subset Selection for Efficient and Robust Learning], 35th AAAI Conference on Artificial Intelligence, AAAI 2021
[2] Krishnateja Killamsetty, Durga Sivasubramanian, Abir De, Ganesh Ramakrishnan, Baharan Mirzasoleiman, Rishabh Iyer, [Grad-Match: A Gradient Matching based Data Selection Framework for Efficient Learning], 2021
[3] Baharan Mirzasoleiman, Jeff Bilmes, and Jure Leskovec. [Coresets for Data-efficient Training of Machine Learning Models]. In International Conference on Machine Learning (ICML), July 2020
[4] Kai Wei, Rishabh Iyer, Jeff Bilmes, [Submodularity in Data Subset Selection and Active Learning], International Conference on Machine Learning (ICML) 2015
[5] Vishal Kaushal, Rishabh Iyer, Suraj Kothiwade, Rohan Mahadev, Khoshrav Doctor, and Ganesh Ramakrishnan, [Learning From Less Data: A Unified Data Subset Selection and Active Learning Framework for Computer Vision], 7th IEEE Winter Conference on Applications of Computer Vision (WACV), 2019 Hawaii, USA
[6] Wei, Kai, et al. [Submodular subset selection for large-scale speech training data], 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2014.
Author:
Research & Development Intern
